【徹底解説】生成AI利用ガイドライン整備、ハズせない3つの原則とは?

社内の生成AI利用を進めるうえで、リスク対策にお悩みの方へ
- 生成AIの利用を検討する中で、リスク対策の取組みが必要になった
- ガイドラインを整備する上でどんなポイントに注意すべき?
こんな悩みはありませんか?
この記事では、生成AI活用を検討する際に押さえておきたい基本的なガイドラインについて、専門用語を使わずに噛み砕いて解説していきます。
また記事の後半では、生成AI・DXの専門家に無料で相談できる「オンライン壁打ち会」についてもご紹介しています。
実際にプロジェクトを進める際の具体的な手法や、弊社nonet 株式会社のサポート内容についても触れています。
似たような悩みをお持ちの方は、ぜひ参考にしてみてください。
- 生成AIの利用検討をもう1ステップ進めるための方法を知る
- 会社の方針として生成AIガイドラインを示す必要性を理解できる
生成AI活用レベルは、早くも差が生まれつつあるが…
 以前からお伝えしている通り、今後の10年程度で生成AIは経営における “必須科目” になると思われますが、日本国内においては早くも生成AI活用格差が生まれつつあるようです。
以前からお伝えしている通り、今後の10年程度で生成AIは経営における “必須科目” になると思われますが、日本国内においては早くも生成AI活用格差が生まれつつあるようです。
国内の大手企業を中心とする企業ではトライ&エラーがある程度ひと回りし、成功事例や失敗事例のノウハウが蓄積されていますが、その一方で中堅〜中小企業では、生成AIの社内利用にさえ検討段階で足踏みしてしまっているケースも少なくありません。
“会社の方針”となる生成AIガイドライン3つの原則
 検討と議論、検討と議論…という足踏みループから抜け出し、生成AI活用をスタートさせるには、やはり“会社の方針”として生成AI活用に関するガイドラインを示す必要があるでしょう。
検討と議論、検討と議論…という足踏みループから抜け出し、生成AI活用をスタートさせるには、やはり“会社の方針”として生成AI活用に関するガイドラインを示す必要があるでしょう。
ここで「ルール」、でも「規約」でもなく「ガイドライン」としているのは、まだまだ生成AI自体が新しい技術であり、状況に応じて適宜更新や改善を前提とした方針にするためです。
これにより、新しいもの好きの従業員たちからの創造的なアイディアを期待できるだけでなく、リスクを管理する方法も示すことができます。
ここではハズせない3つの原則として
- 生成AI、LLMの特性を正しく理解する
- “禁止事項”について明言する
- 生成AIが出力した情報の取り扱い
について考察していきます。
1. 生成AIおよびLLMの特性を正しく理解する
 まず最初に「生成AI(LLM)の特性を理解する」ところから始めていきましょう。
まず最初に「生成AI(LLM)の特性を理解する」ところから始めていきましょう。
ChatGPT(OpenAI社)を始めとする生成AIは、あくまでも大規模言語モデル(LLM、Large Language Models)から学習したデータをもとに、もっとも確率の高い情報を生成している。という点を正しく理解する必要があります。
噛み砕いてお伝えするなら、生成AIは必ずしも事実・真実を生成するものではなく、”もっともらしいウソ(=ハルシネーション)”を生成してしまう可能性がある、と言うことです。
■【関連記事】「生成AIは使えない?」それっぽいウソ=ハルシネーション発生の原因と対策
つまり、これまでのGoogleのような検索エンジンと同じような使い方は避けるべきで、言い換えると「下書き生成」のサービスだと割り切る必要があるワケです。
以上にの理由から、生成AI活用に関するガイドラインでは、生成AIの特性について明確に利用者に示すようにしてください。
とはいえ現実問題、ユーザー側で生成AIの仕組みまで理解できているケースはあまり多くないのが実情です…
実は弊社でも「非エンジニアに向けた生成AIの基礎レクチャー」をご提供していますので、興味がある方はお気軽にお問い合わせください。
2. 入力すべきでない”禁止事項”を定義しよう
 また「禁止事項」として、生成AIとのやり取りで入力すべきでない情報においてもガイドライン化しておきましょう。
また「禁止事項」として、生成AIとのやり取りで入力すべきでない情報においてもガイドライン化しておきましょう。
ここでいう入力すべきでない情報は、具体的にお伝えすると
- 個人情報
- 会社の機密情報
- 倫理的に問題になるような情報
などがあげられます。
…というのも、生成AIに入力したデータ(生成AIとやりとりした履歴)は、大規模言語モデルの学習に利用されること、モデルの提供国で処理される、といった条件が生成AIの利用規約に記載されています。
2024年の6月にはAdobe社が利用規約に相当する”基本利用条件”を改訂し、「ユーザーのコンテンツに対して、限定的な方法で、かつ法律が許容する範囲に限り、アクセス・表示・監視をおこなう」ことがあると明記されました。
※その数日後、世界的な懸念の高まりを受けてAdobe社は「ユーザーコンテンツをAI学習には利用しない」という内容の規約に訂正したようです。
そもそも取扱う情報の機密性が高い企業さまであれば、すでに機密情報取り扱いに関するルールが整備されているとは思いますので、社内方針と利用規約に関するデータの取り扱い方針とでズレや齟齬がないかチェックしておく必要があります。
※以下は、2024年6月10日現在のChatGPTのプライバシーポリシー。
当社は、ChatGPTを動かすモデルをトレーニングするためなど、本サービスを改善するために、お客様から提供されたコンテンツを利用することがあります。
3. 生成AIが出力した”情報の取扱い”を考える
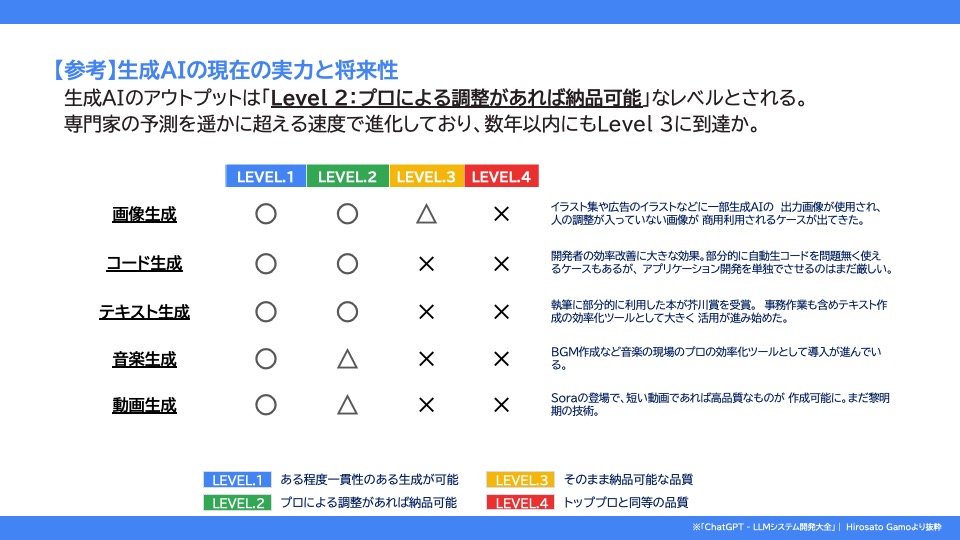 そして3つ目がは「生成AIが出力した情報の取扱い」についてです。
そして3つ目がは「生成AIが出力した情報の取扱い」についてです。
先述した通り、生成AI(LLM)は 必ずしも正しい情報を出力するわけではありません。
今後精度は向上していくと思われますが、生成AIが出力した情報をそのまま“会社の成果物”として納品するのには大きなリスクをはらんでいると言えます。
画像(クリックで拡大できます)で示しているように、人間によるファクトチェック、成果物レビューなどの仕組みについて考えておくべきでしょう。
また、この”それっぽいウソ(=ハルシネーション)”を減らす対応策として、RAG(検索機能拡張)という考え方についても別の記事で解説しています。お時間ある方はぜひ参考にされてみてください。
■【関連記事】「生成AIは使えない?」それっぽいウソ=ハルシネーション発生の原因と対策
《参考》生成AIガイドラインのひな形
東京大学の松尾豊教授が理事長を務める一般社団法人日本ディープラーニング協会(JDLA)のWEBサイトからは、生成AI利用ガイドラインのひな形を無料でダウンロードできます。
イチからガイドライン策定を検討中!という方は、このひな形をたたき台として参考にして論点を整理して頂くのがオススメです。
■《参考》生成AIの利用ガイドライン|日本ディープラーニング協会
生成AIに知見を持つ専門家のサポートが必要ですか?
重ねてになりますが、ここでご紹介したのはあくまでも”一般論”的な内容で、生成AIを検討する際にすべての企業が留意すべきポイントにすぎません。
これを読んで頂いた方の中には、
「うちの業種業態や、ITリテラシーにもマッチするような独自のガイドラインを考えたい…」
という方もいらっしゃるのではないでしょうか?
そのような場合は、弊社のような生成AIに知見のあるパートナー企業を活用いただくのがオススメです。(完全なポジショントークではあります笑)
Google Cloudを活用したDXコンサルティングを提供している nonet 株式会社では、御社の生成AIへの期待値・理解度に合わせて次のようなサービスを提供しており、
- 生成AIの基礎知識レクチャー
- 成功事例から考える、活用方法ワークショップ
- SaaS(月額課金型)の生成AIエージェント提供
- 社内に眠るデータを活用するシステム(RAG)構築
今回のテーマのような生成AI活用の前段階、ガイドラインの検討フェーズから生成AIに関するコンサルティングサービスを提供しています。
もちろん、先述したJDLA提供のひな形をベースにガイドライン作成もサポートいたします。
また、毎月3社限定で「無料オンライン壁打ち会」にて、壁打ちベースでご相談いただける枠を設けております。ガイドライン策定にお困りの方は、せっかくのこの機会をご活用してみてください。

Seeds4biz〜”ビジネスのタネ”がみつかるメディア〜では、
小さな会社に役立つ「デジタル化・DX化」「業務改善」「マーケティング」といったテーマを中心に幅広い情報を発信しています。起業準備中・新規事業やりたい系の人も見てね。